

Machine learning is the branch of computer science that focuses on making computers learn by past experiences and by using a set of data. It is a subset of Artificial intelligence. This is done by designing algorithms that can make computers imitate the way humans learn. Machine learning algorithms make a model based on sample data which is also known as “training data” so that computers can make predictions without being explicitly programmed. ML algorithms are used in a wide range of fields like medical, speech recognition, and computer vision. The term “machine learning” was first coined by Arthur Samuel, an American pioneer in the field of computer gaming and artificial intelligence.
Machine learning can be implemented with artificial neural networks to imitate the working of a human brain. It is the study of making machines more human-like by providing them the ability to build their own programs. This is done without any explicit programming .i.e., minimum human intervention.
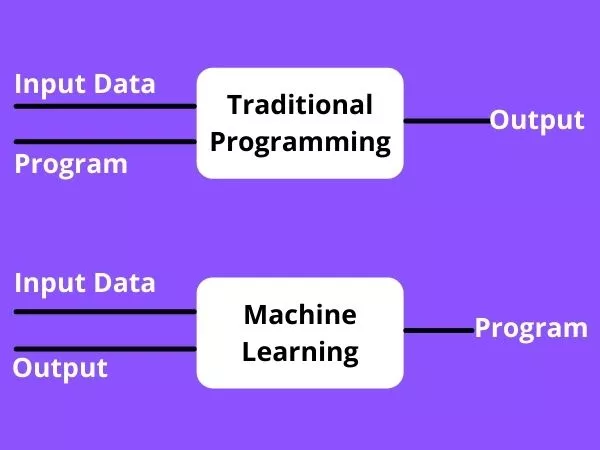
Although the field is related to designing algorithms, it is different from traditional programming. You may wonder, How?
Well, in traditional programming we would give the computer some input data and a well-written and tested program following which, the system would generate some output. In machine learning, we would give the computer input and output data in the learning phase, and the computer works on the required program itself. Look at the image given below.
Why should one learn machine learning?
Machine learning has got all the attention today in the field of computer science. With the help of machine learning, many tasks can be automated most of which can only be done by humans. Giving this ability to the machines can be achieved by machine learning. Many industries are developing robust machine learning models capable of analyzing complex and large sets of data while delivering faster and more accurate results. Machine learning tools enable organizations to more quickly identify opportunities that would result in profit. Not only profit but helps to identify potential risks as well.
How does it work?
UC Berkley broke out the learning system of machine learning into three main parts –
- A decision Process: In general, machine learning algorithms are used to make a prediction or classification. Based on some input data, which can be labeled or unlabeled, your algorithm will produce an estimate of a pattern in the data.
- An error function: An error function serves to evaluate the prediction of the model. If there are known examples, an error function can make a comparison to assess the accuracy of the model.
- Model optimization process: If the model can fit better to the data points in the training set, then weights are adjusted to reduce the discrepancy between the known example and the model estimate. The algorithm will repeat this evaluation and optimize the process, updating weights autonomously until a threshold of accuracy has been met.
Real-World Applications of Machine Learning
Here are a few examples of machine learning that you might see in your everyday life.
Customer Service: Automatic chatbots are replacing human customer care executives. They answer frequently asked questions for topics such as providing personalized advice.
Ecommerce: Ecommerce and social media sites uses machine learning to analyze your search and buying history and recommends the users on other items to purchase.
Financial services: The insights provided by machine learning in this industry allow investors to identify new opportunities or know when to trade. Data mining pinpoints high-risk clients and informs cyber surveillance to find and mitigate signs of fraud. Machine learning can help calibrate financial portfolios or assess risk for loans and insurance underwriting.
Healthcare. The proliferation of wearable sensors and devices that monitor everything from pulse rates and steps walked to oxygen and sugar levels and even sleeping patterns have generated a significant volume of data that enables doctors to assess their patient’s health in real-time. One new machine learning algorithm detects cancerous tumors on mammograms; another identifies skin cancer; a third can analyze retinal images to diagnose diabetic retinopathy.
Programming languages for machine learning
There are many programming languages that are used in the field of machine learning such as R, C++, Java, C#, Julia, Scala, MATLAB, and Python. Python is considered to be the best programming language for machine learning applications by many. This is because python provides various benefits over other languages. Python is the most readable and relatively lower complex language as compared to other programming languages. This makes it much popular among people who are new to programming.
Machine learning applications involve complex concepts like linear algebra and calculus which take a lot of effort and time to implement. Python helps in reducing this burden. Python has a wide range of predefined libraries that makes it suitable for machine learning. These libraries are mentioned below
- Numpy, OpenCV, and Scikit are used when it is needed to work with images.
- Librosa is used for Audio-based applications.
- Matplotlib, Seaborn, and Scikit are used for data representation.
- Scipy for Scientific Computing.
- Pandas is used for high-level data structures and analysis.
- TensorFlow and PyTorch for Deep learning applications.
- NLTK along with NumPy and Scikit is used when working with text.
Terminology of machine learning
Model: A machine learning model which is also known as ‘hypothesis’ is a mathematical representation f a real-world process. A machine learning algorithm along with the training data builds a machine learning model.
Feature: A feature is a measurable property or parameter of the data set.
Feature vector: It is a set of multiple numeric features. We use it as an input to the machine learning model for training and prediction purposes.
Training: An algorithm takes a set of data known as “training data” as input. The learning algorithm finds patterns in the input data and trains the model for expected results (target). The output of the training process is the machine learning model.
Target (Label): The value that the machine learning model has to predict is called the target or label.
Overfitting: When a massive amount of data trains a machine learning model, it tends to learn from the noise and inaccurate data entries. Here the model fails to characterize the data correctly.
Underfitting: It is the scenario when the model fails to decipher the underlying trend in the input data. It destroys the accuracy of the machine learning model. In simple terms, the model or the algorithm does not fit the data well enough.